Vanishing Gradient
Table of Contents
If the gradients are < 1, then as gradients are backpropagated the gradients decrease to near zero (vanishing gradient). Vanishing Gradient cause the model to focus on short term dependencies and ignore long term dependencies.
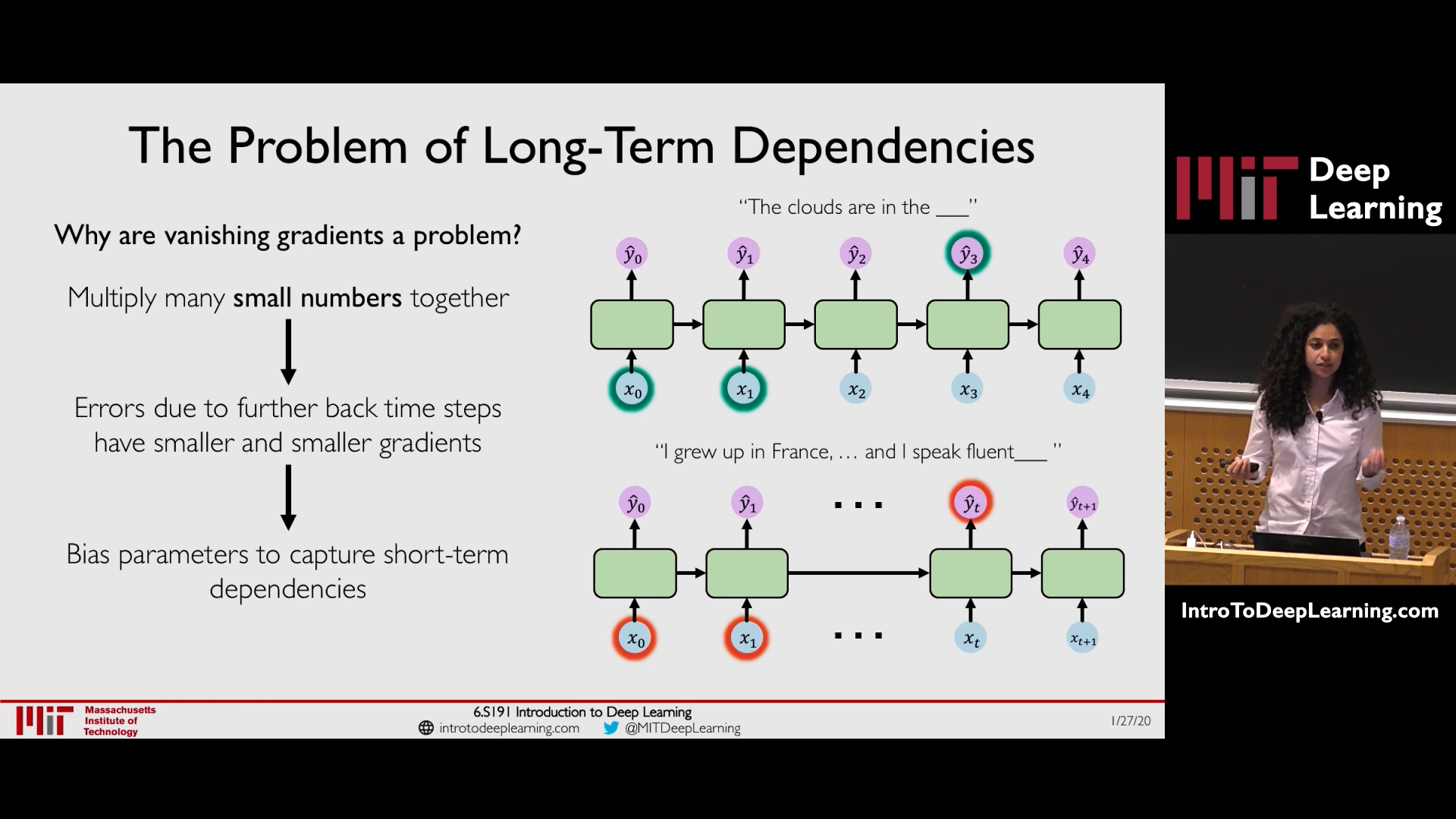
1. Solution to Vanishing Gradient Problem
See Recurrent Neural Network - MIT 6.S191 2020, RNN and Transformers (MIT 6.S191 2022) for links to video lecture.
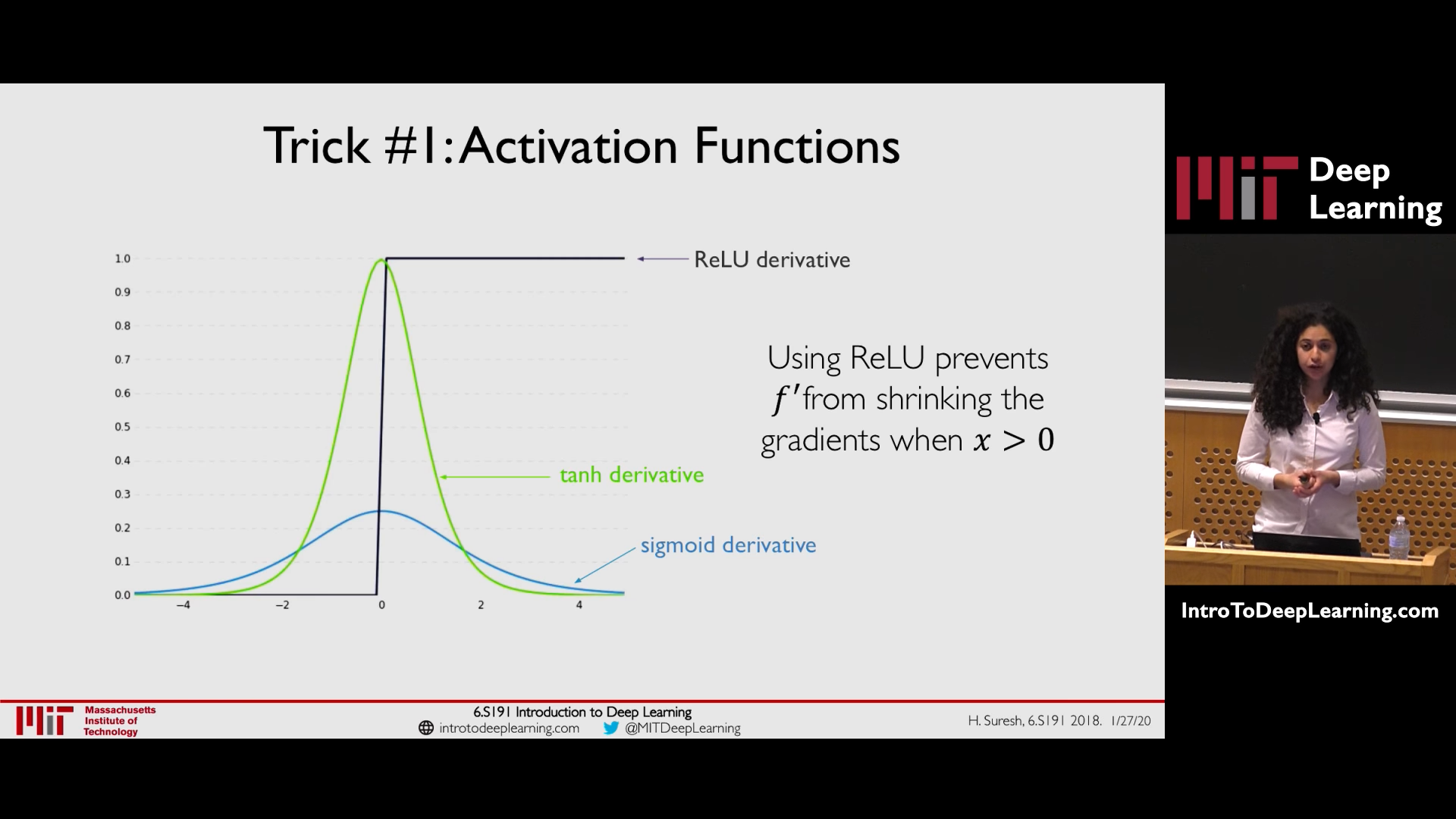
1.1. Trick 1: Activation Function - ReLU (has derivative = 1 or 0)
1.2. Trick 2: Initialized the weights to identity matrix and Bias to zero to prevent rapid shrinking
1.3. Trick 3: Gated Cells (LSTM, GRU, etc)- Best
Use a more complex recurrent unit with gates to control what information is passed through.
2. Vanishing Gradients in Deep Neural Networks
(pg. 252 Deep Learning with Python - François Chollet) In deep networks the noise at each layer can overwhelm the gradient information and backpropagation can stop working.
- Each successive function in the chain introduces some amount of noise.
- This noise starts overwhelming gradient information, If the function chain is too deep,
- and backpropagation stops working.
Your model won’t train at all. This is the vanishing gradients problem.
2.1. Residual Connection
Residual connection acts as an information shortcut around destructive or noisy blocks (such as blocks that contain relu activations or dropout layers), enabling error gradient infor- mation from early layers to propagate noiselessly through a deep network.
